
[참고 풀이]
- '숫자 외의 값들은 무시한다' 를 '숫자 외의 값들은 공백으로 처리한다' 로 처리 "숫자 숫자 숫자 숫자" 와 같이 처리
- .split() 으로 공백을 삭제 (중요 *** split(' ') 와는 달리 split( )은 사이의 공백을 '모두' 제거하여 처리한다.)
def solution(my_string):
s = ''.join(i if i.isdigit() else ' ' for i in my_string)
return sum(int(i) for i in s.split())- 정규식을 이용한 풀이
import re
def solution(my_string):
return sum([int(i) for i in re.findall(r'[0-9]+', my_string)])
[참고 풀이]
- bin(십진수) : 0b1010
- int(문자열, 2) : 문자열을 n진수로 계산해서 십진법으로 결과 반환
def solution(bin1, bin2):
answer = bin(int(bin1,2) + int(bin2,2))[2:]
return answer

[내 풀이]
- 스택이라는 것을 인지를 못했다.
- 되돌리기는 스택 활용하자 !!
def solution(s):
prev = 0
sum = 0
for x in s.split(' '):
if x == 'Z':
sum -= int(prev)
else:
sum += int(x)
prev = x
return sum[참고 풀이]
- 바다코끼리 연산자 := 는 할당과 반환을 동시에 하는 연산자
def solution(s):
answer = 0
for i in range(len(s := s.split(" "))):
answer += int(s[i]) if s[i] != "Z" else -int(s[i-1])
return answer- 스택을 이용한 풀이
def solution(s):
stack = []
for a in s.split():
if a != 'Z':
stack.append(int(a))
else:
if stack:
stack.pop()
return sum(stack)

[내 풀이]
- 나머지가 1, 2, 3, 0 으로 나온다. 내 생각처럼 1, 2, 3, 4 로 나오지 않는다. 그래서 한 번 더 처리를 해주어야 한다.
- (if else 문 조건 없이는 동작하지 않는다!) 사소하지만 실수하기 쉬운 부분. 버릇을 들여두자.
def solution(numbers, k):
return (1 + 2*(k-1)) % len(numbers) if (1 + 2*(k-1)) % len(numbers) !=0 else len(numbers)
[참고 풀이]
- 나머지가 0, 1, 2, 3 으로 나오도록 식을 작성한다.
def solution(numbers, k):
return numbers[2 * (k - 1) % len(numbers)]

[참고 풀이]
- str(배열) 하면 배열의 원소들이 모두 문자열화 된다.
def solution(array):
return str(array).count('7')

[내 풀이]
- 반복되니까 비효율적이다. 그런데 생각이 안났다...
def solution(numbers):
numbers = numbers.replace("one", "1")
numbers = numbers.replace("two", "2")
numbers = numbers.replace("three", "3")
numbers = numbers.replace("four", "4")
numbers = numbers.replace("five", "5")
numbers = numbers.replace("six", "6")
numbers = numbers.replace("seven", "7")
numbers = numbers.replace("eight", "8")
numbers = numbers.replace("nine", "9")
numbers = numbers.replace("zero", "0")
return int(numbers)- zip 을 이용한 풀이가 생각났는데 이게 더 일반적으로 활용되기 좋을 듯 하다.
def solution(numbers):
eng = ["zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"]
num = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
for e, n in zip(eng, num):
numbers = numbers.replace(e, n)
return int(numbers)
[참고 풀이]
- enumerate를 이용해서 인덱스와 값을 각각 배정하여 한 줄로 표현
def solution(numbers):
for num, eng in enumerate(["zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"]):
numbers = numbers.replace(eng, str(num))
return int(numbers)

[내 풀이]
- 정석적인 풀이
- 문자열 슬라이싱은 실제 범위를 초과해서 슬라이싱해도 문제가 발생하지 않는다
ex) "aaaa" 를 [0:8] 로 슬라이싱해도 오류가 발생하지 않음
def solution(my_str, n):
answer = []
i = 0
while i<len(my_str):
answer.append(my_str[i:i+n])
i += n
return answer
[참고 풀이]
- 리스트 컴프리헨션을 이용하면 쉽게 표현 가능하다. 배열안의 값이 모두 간단한 함수에 의해 표현될 수 있는 일정한 규칙이 있는 값들이기 때문이다.
def solution(my_str, n):
return [my_str[i:i+n] for i in range(0, len(my_str), n)]

[내 풀이]
- eval 이라는 함수를 몰라서 고생했다...
#감이 안잡힌다 #공백을 기준으로 값들을 분류해서 정리 후 생각하기
def solution(my_string):
res = 0
buho = '+'
for x in my_string.split(' '):
if x=='+':
buho = '+'
elif x=='-':
buho = '-'
else:
if buho == '+':
res += int(x)
elif buho == '-':
res -= int(x)
return res
[참고 풀이]
- eval 은 문자열로 입력받은 수식을 그대로 계산해주는 함수이다.
solution=eval- 창의적이었던 풀이. -를 그냥 숫자로 계산해버리는 방식
def solution(my_string):
return sum(int(i) for i in my_string.replace(' - ', ' + -').split(' + '))

[참고 풀이]
- math.comb(n, m) : nCm 계산
import math
def solution(balls, share):
return math.comb(balls, share)

[내 풀이]
- 정석적인 풀이
- x_list 와 y_list 대신 그냥 x, y로 리스트 이름을 짓는 게 더 깔끔했을 것 같다.
- 어차피 최대/최소 값만 필요하기 때문에 굳이 정렬할 필요 없이, max(x_list) 와 min(x_list)를 쓰는 게 더 깔끔했을 것 같다.
def solution(dots):
x_list = []
y_list = []
for x, y in dots:
x_list.append(x)
y_list.append(y)
x_list.sort()
y_list.sort()
return (y_list[-1] - y_list[0])*(x_list[-1] - x_list[0])[참고 풀이]
- 순서쌍도 max, min 함수를 적용할 수 있다는 것을 몰랐다.
- max([x, y]) : 오른쪽 위로의 값이 큰 것
- min([x, y]) : 왼쪽 아래로의 값이 큰 것
def solution(dots):
return (max(dots)[0] - min(dots)[0])*(max(dots)[1] - min(dots)[1])

[내 풀이]
- command 보다는 move로 정하는게 더 깔끔했을 수도
- board[0]//2 이 값이 여러번 나오니까 어지럽다.
def solution(keyinput, board):
command = ["up", "down", "left", "right"]
dx = [0, 0, -1, 1]
dy = [1, -1, 0, 0]
x = 0
y = 0
for key in keyinput:
for i in range(len(command)):
if command[i] == key:
nx = x + dx[i]
ny = y + dy[i]
if (-(board[0]//2) <= nx <= (board[0]//2)) and (-(board[1]//2) <= ny <= (board[1]//2)):
x = nx
y = ny
return [x, y]
[참고 풀이]
- x_lim 과 y_lim 을 이용해서 간략하게 표현한 점
- move 라는 네이밍과 딕셔너리를 이용해서 1:1 매칭되게 표현한 점
def solution(keyinput, board):
x_lim,y_lim = board[0]//2,board[1]//2
move = {'left':(-1,0),'right':(1,0),'up':(0,1),'down':(0,-1)}
x,y = 0,0
for k in keyinput:
dx,dy = move[k]
if abs(x+dx)>x_lim or abs(y+dy)>y_lim:
continue
else:
x,y = x+dx,y+dy
return [x,y]- 경계를 벗어나는 값을 max와 min 함수를 이용해서 처리하는 방식
def solution(keyinput, board):
curr = [0, 0]
for k in keyinput:
if k == 'left':
curr[0] = max(curr[0] - 1, -(board[0] // 2))
elif k == 'right':
curr[0] = min(curr[0] + 1, board[0] // 2)
elif k == 'down':
curr[1] = max(curr[1] - 1, -(board[1] // 2))
else:
curr[1] = min(curr[1] + 1, board[1] // 2)
return curr

[내 풀이]
- dict로 변환하지 않아서, for문을 일일이 돌면서 key 값을 찾아내는 모습이 아쉽다.
- dict로 변환했다면 get(key) 로 바로 값을 알아낼 수 있었다.
# 리스트 안의 리스트 안에 있는 값을 검색하고 싶을 땐?
def solution(id_pw, db):
id, pw = id_pw
idYes = False
for d_id, d_pw in db:
if id == d_id:
idYes = True
if pw == d_pw:
return "login"
else:
return "wrong pw"
if not idYes:
return "fail"
[참고 풀이]
- 이중 리스트에서 원소가 두개 여서 가능한 건지 모르겠지만, dict(리스트)가 가능하구나.
- 테스트 결과 dict(db)는 아래 처럼 변환 된다.
{'rardss': '123', 'yyoom': '1234', 'meosseugi': '1234'}def solution(id_pw, db):
if db_pw := dict(db).get(id_pw[0]):
return "login" if db_pw == id_pw[1] else "wrong pw"
return "fail"

[내 풀이]
- 위쪽에 있는 '진료 순서 정하기' 문제랑 똑같은 접근법. 이번엔 응용 성공했다!
def solution(score):
totalScore = [sum(x) for x in score] #[150, 140, 110, 130]
sortedScore = sorted(totalScore, reverse=True) #[150, 140, 130, 110]
return [sortedScore.index(x)+1 for x in totalScore]---

def solution(i, j, k):
totalCount = 0
for x in range(i, j+1):
totalCount += str(x).count(str(k))
return totalCount# 다른 사람 풀이
장점:
1) for문 안에서 어차피 한 줄일 거라면, 리스트 컴프리헨션을 이용하면 앞에 한 줄로 표현 가능(str(i).count(str(k)) 이 부분)
2) 리스트에 담기 때문에 sum( ) 함수 사용 가능
def solution(i, j, k):
answer = sum([ str(i).count(str(k)) for i in range(i,j+1)])
return answer

[내 풀이]
- 너무 복잡해져 버렸다.
def solution(emergency):
#인덱스가 필요하니까 정렬 전에 새로 구성하자 = enumerate
emergency_index = []
for i, x in enumerate(emergency):
emergency_index.append((x, i))
emergency_index.sort(key=lambda x:-x[0])
result = [0] * len(emergency)
for i, (emer, idx) in enumerate(emergency_index):
result[idx] = i+1
return result[참고 풀이]
- 원본 리스트를 유지해두고 그것을 이용해서 풀이.
- 중복 값이 없기 때문에 .index() 를 이용할 수 있다.
def solution(emergency):
return [sorted(emergency, reverse=True).index(e) + 1 for e in emergency]
[내 풀이]
# 바로 풀이가 떠오르지 않았고, 억지로 풀이한 느낌
def solution(my_string):
prevIsDigit=False
temp=""
result=[]
for s in my_string:
if s.isdigit():
if prevIsDigit:
temp+=s
else:
temp=s
prevIsDigit = True
else:
if prevIsDigit:
result.append(temp)
temp = ""
prevIsDigit = False
if temp != "":
result.append(temp)
return sum(int(x) for x in result)[참고 풀이]
- '숫자 외의 값들은 무시한다' 를 '숫자 외의 값들은 공백으로 처리한다' 로 처리 "숫자 숫자 숫자 숫자" 와 같이 처리
- .split() 으로 공백을 삭제 (중요 *** split(' ') 와는 달리 split( )은 사이의 공백을 '모두' 제거하여 처리한다.)
def solution(my_string):
s = ''.join(i if i.isdigit() else ' ' for i in my_string)
return sum(int(i) for i in s.split())- 정규식을 이용한 풀이
import re
def solution(my_string):
return sum([int(i) for i in re.findall(r'[0-9]+', my_string)])
[내 풀이]
- bin( ) 함수와 int( ) 함수의 활용법을 몰라서 비효율적으로 풀이했다.
# 이진수를 십진수로
def calculate(bin):
n = len(bin)
sum = 0
for i, x in enumerate(bin):
sum += 2**(n-1-i)*int(x)
return sum
# 십진수를 이진수로
def tobin(n, sum):
if n == 0:
if sum=='':
return '0'
return sum[::-1]
else:
return tobin(n//2, sum+str(n%2))
def solution(bin1, bin2):
return tobin(calculate(bin1) + calculate(bin2), '')[참고 풀이]
- bin(십진수) : 0b1010
- int(문자열, 2) : 문자열을 n진수로 계산해서 십진법으로 결과 반환
def solution(bin1, bin2):
answer = bin(int(bin1,2) + int(bin2,2))[2:]
return answer
[내 풀이]
- 스택이라는 것을 인지를 못했다.
- 되돌리기는 스택 활용하자 !!
def solution(s):
prev = 0
sum = 0
for x in s.split(' '):
if x == 'Z':
sum -= int(prev)
else:
sum += int(x)
prev = x
return sum[참고 풀이]
- 바다코끼리 연산자 := 는 할당과 반환을 동시에 하는 연산자
def solution(s):
answer = 0
for i in range(len(s := s.split(" "))):
answer += int(s[i]) if s[i] != "Z" else -int(s[i-1])
return answer- 스택을 이용한 풀이
def solution(s):
stack = []
for a in s.split():
if a != 'Z':
stack.append(int(a))
else:
if stack:
stack.pop()
return sum(stack)
[내 풀이]
- 나머지가 1, 2, 3, 0 으로 나온다. 내 생각처럼 1, 2, 3, 4 로 나오지 않는다. 그래서 한 번 더 처리를 해주어야 한다.
- (if else 문 조건 없이는 동작하지 않는다!) 사소하지만 실수하기 쉬운 부분. 버릇을 들여두자.
def solution(numbers, k):
return (1 + 2*(k-1)) % len(numbers) if (1 + 2*(k-1)) % len(numbers) !=0 else len(numbers)
[참고 풀이]
- 나머지가 0, 1, 2, 3 으로 나오도록 식을 작성한다.
def solution(numbers, k):
return numbers[2 * (k - 1) % len(numbers)]
[내 풀이]
- str(배열)이 가능하다는 것을 모르고 일일이 list(map(int)) 로 처리했던 부분이 아쉽다.
def solution(array):
return sum([x.count('7') for x in list(map(str, array))])
[참고 풀이]
- str(배열) 하면 배열의 원소들이 모두 문자열화 된다.
def solution(array):
return str(array).count('7')
[내 풀이]
- 반복되니까 비효율적이다. 그런데 생각이 안났다...
def solution(numbers):
numbers = numbers.replace("one", "1")
numbers = numbers.replace("two", "2")
numbers = numbers.replace("three", "3")
numbers = numbers.replace("four", "4")
numbers = numbers.replace("five", "5")
numbers = numbers.replace("six", "6")
numbers = numbers.replace("seven", "7")
numbers = numbers.replace("eight", "8")
numbers = numbers.replace("nine", "9")
numbers = numbers.replace("zero", "0")
return int(numbers)- zip 을 이용한 풀이가 생각났는데 이게 더 일반적으로 활용되기 좋을 듯 하다.
def solution(numbers):
eng = ["zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"]
num = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
for e, n in zip(eng, num):
numbers = numbers.replace(e, n)
return int(numbers)
[참고 풀이]
- enumerate를 이용해서 인덱스와 값을 각각 배정하여 한 줄로 표현
def solution(numbers):
for num, eng in enumerate(["zero", "one", "two", "three", "four", "five", "six", "seven", "eight", "nine"]):
numbers = numbers.replace(eng, str(num))
return int(numbers)
[내 풀이]
- 정석적인 풀이
- 문자열 슬라이싱은 실제 범위를 초과해서 슬라이싱해도 문제가 발생하지 않는다
ex) "aaaa" 를 [0:8] 로 슬라이싱해도 오류가 발생하지 않음
def solution(my_str, n):
answer = []
i = 0
while i<len(my_str):
answer.append(my_str[i:i+n])
i += n
return answer
[참고 풀이]
- 리스트 컴프리헨션을 이용하면 쉽게 표현 가능하다. 배열안의 값이 모두 간단한 함수에 의해 표현될 수 있는 일정한 규칙이 있는 값들이기 때문이다.
def solution(my_str, n):
return [my_str[i:i+n] for i in range(0, len(my_str), n)]
[내 풀이]
- eval 이라는 함수를 몰라서 고생했다...
-
#감이 안잡힌다 #공백을 기준으로 값들을 분류해서 정리 후 생각하기
def solution(my_string):
res = 0
buho = '+'
for x in my_string.split(' '):
if x=='+':
buho = '+'
elif x=='-':
buho = '-'
else:
if buho == '+':
res += int(x)
elif buho == '-':
res -= int(x)
return res
[참고 풀이]
- eval 은 문자열로 입력받은 수식을 그대로 계산해주는 함수이다.
solution=eval- 창의적이었던 풀이. -를 그냥 숫자로 계산해버리는 방식
def solution(my_string):
return sum(int(i) for i in my_string.replace(' - ', ' + -').split(' + '))
[내 풀이]
- factorial 함수 활용할 거였으면 그냥 comb 함수를 활용하는 게 나았다. (comb함수를 잊고 있었다)
from math import factorial
def solution(balls, share):
return factorial(balls) / factorial(balls-share) / factorial(share)
[참고 풀이]
- math.comb(n, m) : nCm 계산
import math
def solution(balls, share):
return math.comb(balls, share)
[내 풀이]
- 정석적인 풀이
- x_list 와 y_list 대신 그냥 x, y로 리스트 이름을 짓는 게 더 깔끔했을 것 같다.
- 어차피 최대/최소 값만 필요하기 때문에 굳이 정렬할 필요 없이, max(x_list) 와 min(x_list)를 쓰는 게 더 깔끔했을 것 같다.
def solution(dots):
x_list = []
y_list = []
for x, y in dots:
x_list.append(x)
y_list.append(y)
x_list.sort()
y_list.sort()
return (y_list[-1] - y_list[0])*(x_list[-1] - x_list[0])[참고 풀이]
- 순서쌍도 max, min 함수를 적용할 수 있다는 것을 몰랐다.
- max([x, y]) : 오른쪽 위로의 값이 큰 것
- min([x, y]) : 왼쪽 아래로의 값이 큰 것
def solution(dots):
return (max(dots)[0] - min(dots)[0])*(max(dots)[1] - min(dots)[1])
[내 풀이]
- command 보다는 move로 정하는게 더 깔끔했을 수도
- board[0]//2 이 값이 여러번 나오니까 어지럽다.
def solution(keyinput, board):
command = ["up", "down", "left", "right"]
dx = [0, 0, -1, 1]
dy = [1, -1, 0, 0]
x = 0
y = 0
for key in keyinput:
for i in range(len(command)):
if command[i] == key:
nx = x + dx[i]
ny = y + dy[i]
if (-(board[0]//2) <= nx <= (board[0]//2)) and (-(board[1]//2) <= ny <= (board[1]//2)):
x = nx
y = ny
return [x, y]
[참고 풀이]
- x_lim 과 y_lim 을 이용해서 간략하게 표현한 점
- move 라는 네이밍과 딕셔너리를 이용해서 1:1 매칭되게 표현한 점
def solution(keyinput, board):
x_lim,y_lim = board[0]//2,board[1]//2
move = {'left':(-1,0),'right':(1,0),'up':(0,1),'down':(0,-1)}
x,y = 0,0
for k in keyinput:
dx,dy = move[k]
if abs(x+dx)>x_lim or abs(y+dy)>y_lim:
continue
else:
x,y = x+dx,y+dy
return [x,y]- 경계를 벗어나는 값을 max와 min 함수를 이용해서 처리하는 방식
def solution(keyinput, board):
curr = [0, 0]
for k in keyinput:
if k == 'left':
curr[0] = max(curr[0] - 1, -(board[0] // 2))
elif k == 'right':
curr[0] = min(curr[0] + 1, board[0] // 2)
elif k == 'down':
curr[1] = max(curr[1] - 1, -(board[1] // 2))
else:
curr[1] = min(curr[1] + 1, board[1] // 2)
return curr
[내 풀이]
- dict로 변환하지 않아서, for문을 일일이 돌면서 key 값을 찾아내는 모습이 아쉽다.
- dict로 변환했다면 get(key) 로 바로 값을 알아낼 수 있었다.
# 리스트 안의 리스트 안에 있는 값을 검색하고 싶을 땐?
def solution(id_pw, db):
id, pw = id_pw
idYes = False
for d_id, d_pw in db:
if id == d_id:
idYes = True
if pw == d_pw:
return "login"
else:
return "wrong pw"
if not idYes:
return "fail"
[참고 풀이]
- 이중 리스트에서 원소가 두개 여서 가능한 건지 모르겠지만, dict(리스트)가 가능하구나.
- 테스트 결과 dict(db)는 아래 처럼 변환 된다.
{'rardss': '123', 'yyoom': '1234', 'meosseugi': '1234'}def solution(id_pw, db):
if db_pw := dict(db).get(id_pw[0]):
return "login" if db_pw == id_pw[1] else "wrong pw"
return "fail"
[내 풀이]
- 위쪽에 있는 '진료 순서 정하기' 문제랑 똑같은 접근법. 이번엔 응용 성공했다!
def solution(score):
totalScore = [sum(x) for x in score] #[150, 140, 110, 130]
sortedScore = sorted(totalScore, reverse=True) #[150, 140, 130, 110]
return [sortedScore.index(x)+1 for x in totalScore]---
- b //= gcd(a,b) 기약분수 만들기 (분모)
- a //= gcd(a,b) 기약분수 만들기 (분자)
- 똑같은 걸 이어 붙여서 그 안에 공통값 있는 지 찾는 것. 이 idea도 예전에 본 적이 있었다. (원으로 생긴 것을 일자로 펴서 생각하려면 *2 해서 생각하면 된다)
- 다항식 표현할 때 실수 많이하는 것: 1x+3 과 같이 표현하지 않는다는 것. x+3 과 같이 표현해주어야 한다.
- 형식에 맞춰 출력할 때 f'{변수이름}와 {변수이름}가 문제를 풀고 있다.' 과 같이 표현

[내 풀이]
- 빈도 수 기준으로 값을 묶어 표현하려고 했다. 그래서 딕셔너리를 {빈도:항목} 으로 구성한 후,
- max(빈도)의 항목 값을 반환하되 항목 값이 여러 개일 경우 -1을 반환
# 한 번에 생각 안 남
def solution(array):
dic = dict()
for x in array:
dic[array.count(x)] = list(set(dic.get(array.count(x), []) + [x]))
return dic[max(dic.keys())][0] if len(dic[max(dic.keys())])==1 else -1
[참고 풀이]
- set을 이용해서 하나씩만 제거 후 마지막 남는 것이 뭔지 확인하고, 그것을 결과값으로 반환
def solution(array):
while len(array) != 0:
for i, a in enumerate(set(array)):
array.remove(a)
if i == 0: return a
return -1---
- a,b,c = common[:3] 과 같이 한 번에 값 깔끔하게 할당했다.
- set.update 는 set에 여러 값을 한 번에 추가할 때 사용하는 메서드이다. 기존 집합.update({추가할 집합}) 과 같이 사용한다.
- A.isdisjoint(B) : A와 B는 공통요소가 하나도 없다.











# 특정 조건인 것들을 제거 하는 것 : Counter 활용해서 특정 조건을 뺄셈할 수 있었다.
# 내 풀이
def solution(participant, completion):
for par in participant:
if par not in completion:
return par
# 해시 값으로 무슨 값이었는지 추적할 수 있다는 아이디어
def solution(participant, completion):
dict = {}
sumhash = 0
for part in participant:
dict[hash(part)] = part
sumhash += hash(part)
for comp in completion:
sumhash -= hash(comp)
return dict[sumhash]
# 참고 풀이
# from collections import Counter / Counter 활용하기
# Counter 객체 서로 뺄셈이 가능하다!
import collections
def solution(participant, completion):
answer = collections.Counter(participant) - collections.Counter(completion)
return list(answer.keys())[0]





# 내 풀이
- mul = 1부터 for 문을 한 줄로 표현할 수 있다.
from collections import Counter
def solution(clothes):
counter = Counter(map(lambda x:x[1],clothes))
mul = 1
for value in counter.values():
mul *= (value+1)
return mul - 1
# 참고풀이
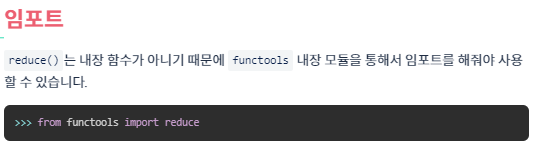
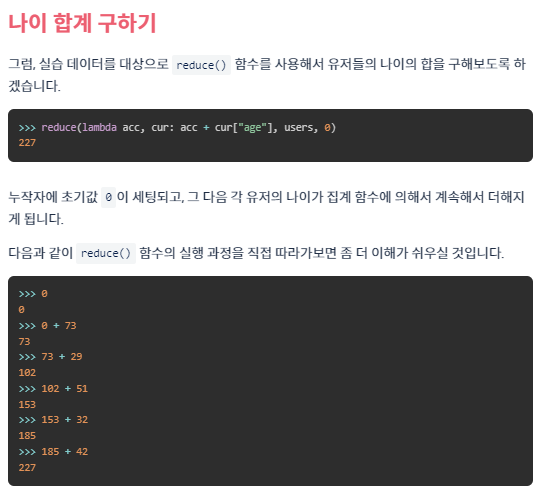
- reduce(집계 함수, 순회 가능한 데이터, [초기값]) /from collections import reduce
- x는 초기값, y는 리스트에서 처음 값 부터 하나씩 계산되는 값
def solution(clothes):
from collections import Counter
from functools import reduce
cnt = Counter([kind for name, kind in clothes])
answer = reduce(lambda x, y: x*(y+1), cnt.values(), 1) - 1
return answer


# 내 풀이
# 장르 우선순위 깔끔하게 표현하는 법?
- 참고풀이1 과 비교 할 때, d는 dic, total_play는 genreSort 로 똑같이 데이터를 정리해두고 값을 정렬로 뽑았는데, 코드는 참고풀이1이 훨씬 간결해보인다.
- 풀이1에서는 d를 먼저 정의해두고, 이를 이용해서 genreSort를 한 줄에 바로 구했기 때문이다.
def solution(genres, plays):
answer = []
total_play = {}
for i, x in enumerate(genres):
total_play[x] = total_play.get(x, 0) + plays[i]
total_play = sorted(total_play.items(), key=lambda x: -x[1])
total_play = [x[0] for x in total_play]
dic = dict()
for i, (genre, play) in enumerate(zip(genres, plays)):
dic[genre] = dic.get(genre, []) + [(play, i)]
for genre in total_play:
answer += [x[1] for x in sorted(dic[genre], key=lambda x: (-x[0], x[1]))[:2]]
return answer
# 참고풀이 1
- d = {e:[] for e in set(genres)} 이렇게 딕셔너리도 리스트처럼 초기화 할 수 있구나.
- temp[:min(len(temp), 2)] 이렇게 표현할 수 있었구나.
def solution(genres, plays):
answer = []
d = {e:[] for e in set(genres)}
for e in zip(genres, plays, range(len(plays))):
d[e[0]].append([e[1] , e[2]])
genreSort =sorted(list(d.keys()), key= lambda x: sum( map(lambda y: y[0],d[x])), reverse = True)
for g in genreSort:
temp = [e[1] for e in sorted(d[g],key= lambda x: (x[0], -x[1]), reverse = True)]
answer += temp[:min(len(temp),2)]
return answer
# 참고풀이 2
- 파이썬 class에서 self이런 거랑 같이 나오는 풀이들을 이해를 못한다. 이 부분을 배워 두자.
def solution(genres, plays):
answer = []
dic = {}
album_list = []
for i in range(len(genres)):
dic[genres[i]] = dic.get(genres[i], 0) + plays[i]
album_list.append(album(genres[i], plays[i], i))
dic = sorted(dic.items(), key=lambda dic:dic[1], reverse=True)
album_list = sorted(album_list, reverse=True)
while len(dic) > 0:
play_genre = dic.pop(0)
print(play_genre)
cnt = 0;
for ab in album_list:
if play_genre[0] == ab.genre:
answer.append(ab.track)
cnt += 1
if cnt == 2:
break
return answer
class album:
def __init__(self, genre, play, track):
self.genre = genre
self.play = play
self.track = track
def __lt__(self, other):
return self.play < other.play
def __le__(self, other):
return self.play <= other.play
def __gt__(self, other):
return self.play > other.play
def __ge__(self, other):
return self.play >= other.play
def __eq__(self, other):
return self.play == other.play
def __ne__(self, other):
return self.play != other.play# 내 풀이
# 장르 우선순위 깔끔하게 표현하는 법?
- 참고풀이1 과 비교 할 때, d는 dic, total_play는 genreSort 로 똑같이 데이터를 정리해두고 값을 정렬로 뽑았는데, 코드는 참고풀이1이 훨씬 간결해보인다.
- 풀이1에서는 d를 먼저 정의해두고, 이를 이용해서 genreSort를 한 줄에 바로 구했기 때문이다.
def solution(genres, plays):
answer = []
total_play = {}
for i, x in enumerate(genres):
total_play[x] = total_play.get(x, 0) + plays[i]
total_play = sorted(total_play.items(), key=lambda x: -x[1])
total_play = [x[0] for x in total_play]
dic = dict()
for i, (genre, play) in enumerate(zip(genres, plays)):
dic[genre] = dic.get(genre, []) + [(play, i)]
for genre in total_play:
answer += [x[1] for x in sorted(dic[genre], key=lambda x: (-x[0], x[1]))[:2]]
return answer
# 참고풀이 1
- d = {e:[] for e in set(genres)} 이렇게 딕셔너리도 리스트처럼 초기화 할 수 있구나.
- temp[:min(len(temp), 2)] 이렇게 표현할 수 있었구나.
def solution(genres, plays):
answer = []
d = {e:[] for e in set(genres)}
for e in zip(genres, plays, range(len(plays))):
d[e[0]].append([e[1] , e[2]])
genreSort =sorted(list(d.keys()), key= lambda x: sum( map(lambda y: y[0],d[x])), reverse = True)
for g in genreSort:
temp = [e[1] for e in sorted(d[g],key= lambda x: (x[0], -x[1]), reverse = True)]
answer += temp[:min(len(temp),2)]
return answer
# 참고풀이 2
- 파이썬 class에서 self이런 거랑 같이 나오는 풀이들을 이해를 못한다. 이 부분을 배워 두자.
def solution(genres, plays):
answer = []
dic = {}
album_list = []
for i in range(len(genres)):
dic[genres[i]] = dic.get(genres[i], 0) + plays[i]
album_list.append(album(genres[i], plays[i], i))
dic = sorted(dic.items(), key=lambda dic:dic[1], reverse=True)
album_list = sorted(album_list, reverse=True)
while len(dic) > 0:
play_genre = dic.pop(0)
print(play_genre)
cnt = 0;
for ab in album_list:
if play_genre[0] == ab.genre:
answer.append(ab.track)
cnt += 1
if cnt == 2:
break
return answer
class album:
def __init__(self, genre, play, track):
self.genre = genre
self.play = play
self.track = track
def __lt__(self, other):
return self.play < other.play
def __le__(self, other):
return self.play <= other.play
def __gt__(self, other):
return self.play > other.play
def __ge__(self, other):
return self.play >= other.play
def __eq__(self, other):
return self.play == other.play
def __ne__(self, other):
return self.play != other.play
'복습노트' 카테고리의 다른 글
| [인프런] spring MVC 1편 (0) | 2023.05.25 |
|---|

댓글