https://www.boostcourse.org/cs112/lecture/118997?isDesc=false
모두를 위한 컴퓨터 과학 (CS50 2019)
부스트코스 무료 강의
www.boostcourse.org
비트
정보를 저장하고 연산을 수행하기 위해 컴퓨터는 비트(bit)라는 측정 단위를 씁니다. 비트는 이진 숫자라는 뜻을 가진 “binary digit”의 줄임말이며, 0과 1, 두 가지 값만 가질 수 있는 측정 단위입니다.
바이트(byte)는 여덟 개의 비트가 모여 만들어진 것입니다. 하나의 바이트에 여덟 개의 비트가 있고, 비트 하나는 0과 1로 표현될 수 있기 때문에 2^8 = 256 개의 서로 다른 바이트
문자의 표현
그 중 하나는 설명미국정보교환표준부호 ASCII(아스키코드/American Standard Code for Information Interchange) 입니다.
총 128개의 부호로 정의되어 있는데, 가령 알파벳 A는 10진수 기준으로 65, 알파벳 B는 66로 되어있습니다.

이 외에도 Unicode라는 표준에서는 더 많은 비트를 사용하여 더 다양한 다른 문자들도 표현가능 하도록 지원하고 있습니다. ASCII로는 문자들을 표현하기에 충분하지 않았기 때문입니다.
Unicode는 😂(기쁨의 눈물) 이런 이모티콘 까지 표현할 수 있게 해주었습니다. 이 이모티콘은 10진법으로 128,514입니다. 2진법으로는 11111011000000010 입니다.
C언어
#include <stdio.h>는 “stdio.h”라는 이름의 파일을 찾아서 “printf” 함수에 접근할 수 있도록 해줍니다.
이게 무슨 말일까? 라고 생각이 드실 거라고 생각이 듭니다.
하지만 이것은 지금 크게 중요하지 않습니다.
오늘 제일 중요한 것은 중간에 있는 printf("hello, world")입니다.
우리가 Word로 문서를 저장했을때 "문서.docx"와 같이 .docx가 붙는 것 처럼,
C로 작성한 코드는 “파일이름.c”로 저장해야 합니다. (확장자 “.c”는 C로 작성된 코드라는 의미입니다.)
마이크로소프트의 Word 처럼 자동적으로 붙여주지 않기 때문에 C의 경우에는 직접 .c를 붙여줘야 합니다.
컴파일러
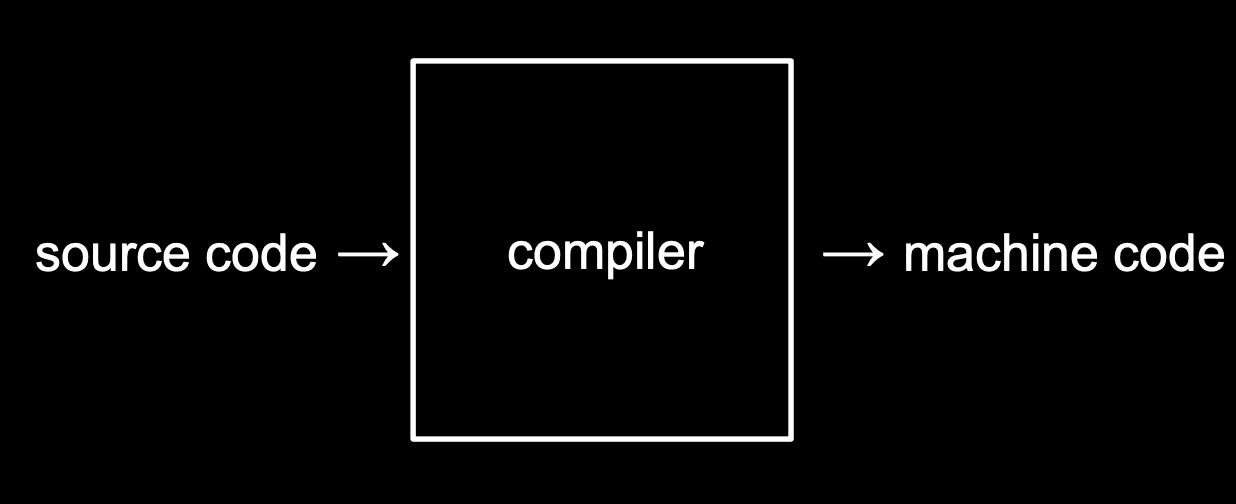
우리가 직접 작성한 코드는 “소스 코드” 라고 불립니다. 이를 2진수로 작성된 “머신 코드”로 변환해야 컴퓨터가 이해할 수 있습니다. 이런 작업을 컴파일러라는 프로그램이 수행해줍니다.
터미널창의 명령어 프롬프트에서 “$” 기호 옆에우리가 원하는 명령어를 입력하면 됩니다.
clang hello.c 라는 명령어는 “clang” 이라는 컴파일러로 “hello.c”라는 코드를 컴파일하라는 의미입니다.
그 결과 a.out 이라는 파일이 생성됩니다.
./a. out 이라는 명령어를 실행하면 컴퓨터가 현재 디렉토리에 있는 a.out이라는 프로그램을 실행하게 해줍니다.
(./a. out에서 제일 앞에 있는 .은 지금 있는 현재 폴더를 나타냅니다.)
형식 지정자
printf 함수에서는 각 데이터 타입을 위한 형식 지정자를 사용할 수 있습니다.
지난 강의에서 문자열(string)인 answer 변수의 인자를 %s로 불러온 것을 기억하시나요?
이번에는 여러가지 데이터 타입 마다 사용되는 형식 지정자를 알아보도록 하겠습니다.
- %c : char
- %f : float, double
- %i : int
- %li : long
- %s : string
컴퓨터는 RAM(랜덤 액세스 메모리)이라는 물리적 저장장치를 포함하고 있습니다. 우리가 작성한 프로그램은 구동 중에 RAM에 저장되는데요, RAM은 유한한 크기의 비트만 저장할 수 있기 때문에 때때로 부정확한 결과를 내기도 합니다.
부동 소수점 부정확성
아래와 같이 실수 x, y를 인자로 받아 x 나누기 y를 하는 프로그램이 있다고 해봅시다.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
// 사용자에게 x 값 받기
float x = get_float("x: ");
// 사용자에게 y 값 받기
float y = get_float("y: ");
// 나눗셈 후 출력
printf("x / y = %.50f\n", x / y);
}
나눈 결과를 소수점 50자리까지 출력하기로 하고, x에 1을, y에 10을 입력하면 아래와 같은 결과가 나옵니다.
x: 1
y: 10
x / y = 0.10000000149011611938476562500000000000000000000000정확한 결과는 0.1이 되어야 하지만, float 에서 저장 가능한 비트 수가 유한하기 때문에 다소 부정확한 결과를 내게 되는 것입니다.
정수 오버플로우
비슷한 오류로, 1부터 시작하여 2를 계속해서 곱하여 출력하는 아래와 같은 프로그램이 있다고 해봅시다.
#include <stdio.h>
#include <unistd.h>
int main(void)
{
for (int i = 1; ; i *= 2)
{
printf("%i\n", i);
sleep(1);
}
}우리가 변수 i를 int로 저장하기 때문에, 2를 계속 곱하다가 int 타입이 저장할 수 있는 수를 넘은 이후에는 아래와 같은 에러와 함께 0이 출력될 것입니다.
...
1073741824
overflow.c:6:25: runtime error: signed integer overflow: 1073741824 * 2 cannot be represented in type 'int'
-2147483648
0
0
...
정수를 계속 키우는 프로그램에서 10억을 넘기자 앞으로 넘어갈 1의 자리가 없어진 것입니다.
int에서는 32개의 비트가 다였기 때문입니다. 그 이상의 숫자는 저장할 수 없는 것입니다.
이런 오버플로우 문제는 실생활에서도 종종 발견됩니다.
1999년에 큰 이슈가 되었던 Y2K 문제는 연도를 마지막 두 자리수로 저장했던 관습 때문에 새해가 오면 ‘99’에서 ‘00’으로 정수 오버플로우가 발생하고, 새해가 2000년이 아닌 1900년으로 인식된다는 문제였습니다.
그리고 세계는 수백만 달러를 투자해서 프로그래머들에게 더 많은 메모리를 활용해서 이를 해결하도록 하였습니다.
이는 통찰력 부족으로 발생한 아주 현실적이고 값비싼 문제였습니다.
또한 다른 사례로 비행기 보잉 787에서 구동 후 248일이 지나면 모든 전력을 잃는 문제가 있었습니다.
왜냐하면 강제로 안전 모드로 진입하였기 때문입니다.
이는 소프트웨어의 변수가 248일이 지난 뒤에 오버플로우가되어 발생하였기 때문이었습니다.
248일을 1/100초로 계산하면 대략 2의 32제곱이 나옵니다.
보잉을 설계할때 사용한 변수보다 너무 커졌던 것입니다.
이를 해결하기 위해 주기적으로 재가동을 하여 변수를 다시 0으로 리셋했습니다.
따라서 다루고자 하는 데이터 값의 범위를 유의하며 프로그램을 작성하는 것이 중요합니다.
지금까지는 아무것도 모른채 마구잡이로 쓴 코드가 잘 돌아갔다면 이제부터는 연습과 응용을 통해 동작 원리를 이해할 수 있을 것입니다.
우선 첫 수업에 봤던 예제를 다시 살펴보며 지금 사용하는 방법이 그때 우리가 사용한 방법과 어떻게 다른지 알아봅시다.
첫 수업에 봤던 C코드를 다시 봐보겠습니다.
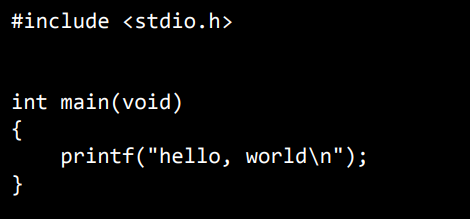
우선 main이라는 함수가 있습니다. 프로그램의 시작점으로써 실행 버튼을 클릭하는 것과 같습니다.
printf는 출력을 담당하는 함수입니다.
printf 함수를 사용하기 위해서는 stdio.h 라이브러리가 필요합니다.
정확히 말하면 stdio.h는 헤더 파일로 C언어로 작성되어 있으며 파일명이 .h로 끝나는 파일입니다.
이 파일에는 printf 함수의 프로토타입이 있어서 Clang 컴파일러가 프로그램을 컴파일할때 printf가 무엇인지 알려주는 역할을 합니다.
코드를 clang hello.c로 컴파일하고 ./a.out 명령으로 프로그램을 실행할 때 이 과정은 컴퓨터가 이해하는 0과 1로 가득찬 파일 a.out을 생성하여 실행 가능하게 합니다.
이해하기 어려운 이 과정에 대한 이해는 잠시 미뤄두고 우선 넘어가보도록 하겠습니다.
만약 a.out과 다른 이름(hello)으로 컴파일을 하고 싶다면 아래와 같이 명령행 인자를 추가해야줘야 합니다.
clang -o hello hello.c우리는 또한 CS50 라이브러리를 사용해 보았습니다.
이 처럼 CS50 라이브러리를 사용한 프로그램을 컴파일 할때는 clang에 또 하나의 프로그램(-lcs50)이 필요했습니다.
그래야 clang이 실행되었습니다.
clang -o hello hello.c -lcs50이는 clang에게 CS50 라이브러리에 있는 모든 0과 1들을 여기에 연결하라는 의미입니다.
더 간단히는, 이 전에 배웠듯이 make 프로그램을 이용하면 이 모든 컴파일 과정을 자동으로 처리할 수 있습니다.
make나 clang을 사용해서 프로그램을 실행할 때 아래 네 개의 단계를 거칩니다.
- 전처리
- 컴파일링
- 어셈블링
- 링킹
우리가 명령어를 실행할 때 정확히 어떤 일이 일어나는지 알아보도록 하겠습니다.
전처리(Precompile)
컴파일의 전체 과정은 네 단계로 나누어볼 수 있습니다. 그 중 첫 번째 단계는 전처리인데, 전처리기에 의해 수행됩니다. # 으로 시작되는 C 소스 코드는 전처리기에게 실질적인 컴파일이 이루어지기 전에 무언가를 실행하라고 알려줍니다.
예를 들어, #include는 전처리기에게 다른 파일의 내용을 포함시키라고 알려줍니다. 프로그램의 소스 코드에 #include 와 같은 줄을 포함하면, 전처리기는 새로운 파일을 생성하는데 이 파일은 여전히 C 소스 코드 형태이며 stdio.h 파일의 내용이 #include 부분에 포함됩니다.
컴파일(Compile)
전처리기가 전처리한 소스 코드를 생성하고 나면 그 다음 단계는 컴파일입니다. 컴파일러라고 불리는 프로그램은 C 코드를 어셈블리어라는 저수준 프로그래밍 언어로 컴파일합니다.
어셈블리는 C보다 연산의 종류가 훨씬 적지만, 여러 연산들이 함께 사용되면 C에서 할 수 있는 모든 것들을 수행할 수 있습니다. C 코드를 어셈블리 코드로 변환시켜줌으로써 컴파일러는 컴퓨터가 이해할 수 있는 언어와 최대한 가까운 프로그램으로 만들어 줍니다. 컴파일이라는 용어는 소스 코드에서 오브젝트 코드로 변환하는 전체 과정을 통틀어 일컫기도 하지만, 구체적으로 전처리한 소스 코드를 어셈블리 코드로 변환시키는 단계를 말하기도 합니다.
어셈블(Assemble)
소스 코드가 어셈블리 코드로 변환되면, 다음 단계인 어셈블 단계로 어셈블리 코드를 오브젝트 코드로 변환시키는 것입니다. 컴퓨터의 중앙처리장치가 프로그램을 어떻게 수행해야 하는지 알 수 있는 명령어 형태인 연속된 0과 1들로 바꿔주는 작업이죠. 이 변환작업은 어셈블러라는 프로그램이 수행합니다. 소스 코드에서 오브젝트 코드로 컴파일 되어야 할 파일이 딱 한 개라면, 컴파일 작업은 여기서 끝이 납니다. 그러나 그렇지 않은 경우에는 링크라 불리는 단계가 추가됩니다.
링크(Link)
만약 프로그램이 (math.h나 cs50.h와 같은 라이브러리를 포함해) 여러 개의 파일로 이루어져 있어 하나의 오브젝트 파일로 합쳐져야 한다면 링크라는 컴파일의 마지막 단계가 필요합니다. 링커는 여러 개의 다른 오브젝트 코드 파일을 실행 가능한 하나의 오브젝트 코드 파일로 합쳐줍니다. 예를 들어, 컴파일을 하는 동안에 CS50 라이브러리를 링크하면 오브젝트 코드는 GetInt()나 GetString() 같은 함수를 어떻게 실행할 지 알 수 있게 됩니다.
이 네 단계를 거치면 최종적으로 실행 가능한 파일이 완성됩니다.
--
더 좋은 방법은 아래 코드와 같이 새로운 자료형으로 구조체를 정의해서 이름과 번호를 묶어주는 것입니다.
#include <cs50.h>
#include <stdio.h>
#include <string.h>
typedef struct
{
string name;
string number;
}
person;
int main(void)
{
person people[4];
people[0].name = "EMMA";
people[0].number = "617–555–0100";
people[1].name = "RODRIGO";
people[1].number = "617–555–0101";
people[2].name = "BRIAN";
people[2].number = "617–555–0102";
people[3].name = "DAVID";
people[3].number = "617–555–0103";
// EMMA 검색
for (int i = 0; i < 4; i++)
{
if (strcmp(people[i].name, "EMMA") == 0)
{
printf("Found %s\n", people[i].number);
return 0;
}
}
printf("Not found\n");
return 1;
}
person 이라는 이름의 구조체를 자료형으로 정의하고 person 자료형의 배열을 선언하면 그 안에 포함된 속성값은 ‘.’으로 연결해서 접근할 수 있습니다.
person a; 라는 변수가 있다면, a.name 또는 a.number 이 각각 이름과 전화번호를 저장하는 변수가 되겠죠.
이렇게 함으로써 더욱 확장성 있는 전화번호부 검색 프로그램을 만들 수 있습니다.
--
높이를 입력 받아 중첩 루프를 통해 피라미드를 출력해주는 draw 함수를 정의한 것이죠.
여기서 꼭 중첩 루프를 써야만 할까요? 사실 바깥 쪽 루프는 안 쪽 루프에서 수행하는 내용을 반복하도록 하는 것일 뿐입니다.
따라서 바깥 쪽 루프를 없앤 draw함수를 만들고, 이를 ‘재귀적으로’ 호출하도록 해서 똑같은 작업을 수행할 수 있습니다.
즉, draw 함수 안에서 draw 함수를 호출 하는 것이죠. 아래 코드와 같이 수정할 수 있습니다.
#include <cs50.h>
#include <stdio.h>
void draw(int h);
int main(void)
{
int height = get_int("Height: ");
draw(height);
}
void draw(int h)
{
// 높이가 0이라면 (그릴 필요가 없다면)
if (h == 0)
{
return;
}
// 높이가 h-1인 피라미드 그리기
draw(h - 1);
// 피라미드에서 폭이 h인 한 층 그리기
for (int i = 0; i < h; i++)
{
printf("#");
}
printf("\n");
}
draw 함수 안에서 draw 함수를 다시 호출 하는 부분을 유의하시기 바랍니다.
h라는 높이를 받았을 때, h-1 높이로 draw 함수를 먼저 호출하고, 그 후에 h 만큼의 #을 출력합니다. 여기서 내부적으로 호출된 draw 함수를 따라가다 보면 h = 0인 상황이 오게 됩니다.
따라서 그 때는 아무것도 출력을 하지 않도록 하는 조건문을 추가해줘야 합니다.
이렇게 재귀를 사용하면 중첩 루프를 사용하지 않고도 하나의 함수로 동일한 작업을 수행할 수 있습니다.
--
지난 강의에서 아래 그림과 같은 메모리 구조를 간략하게 배웠었습니다.
다시 복습하면, 머신 코드 영역에는 우리 프로그램이 실행될 때 그 프로그램이 컴파일된 바이너리가 저장됩니다.
글로벌 영역에는 프로그램 안에서 저장된 전역 변수가 저장됩니다.
힙 영역에는 malloc으로 할당된 메모리의 데이터가 저장됩니다. 그리고 스택에는 프로그램 내의 함수와 관련된 것들이 저장됩니다.

힙 영역에서는 malloc 에 의해 메모리가 더 할당될수록, 점점 사용하는 메모리의 범위가 아래로 늘어납니다.
마찬가지로 스택 영역에서도 함수가 더 많이 호출 될수록 사용하는 메모리의 범위가 점점 위로 늘어납니다.
이렇게 점점 늘어나다 보면 제한된 메모리 용량 하에서는 기존의 값을 침범하는 상황도 발생할 것입니다.
이를 힙 오버플로우 또는 스택 오버플로우라고 일컫습니다.
--
int main(void)
{
int *x;
int *y;
x = malloc(sizeof(int));
*x = 42;
*y = 13;
}main 함수 안의 첫 두 줄에서는 포인터 x와 y를 선언합니다.
그리고 x에는 malloc 함수를 이용해서 int 자료형 크기에 해당하는 메모리를 할당합니다.
그 다음에는 x와 y 포인터가 가리키는 지점에 각각 42와 13을 저장합니다.
여기서 문제가 될 만한 부분은 *y = 13 입니다. y는 포인터로만 선언되었을 뿐이지, 어디를 가리킬지에 대해서는 아직 정의가 되지 않았습니다.
따라서 초기화 되지 않은 *y는 프로그램 어딘가를 임의로 가리키고 있을 수도 있습니다.
따라서 그 곳에 13이라는 값을 저장하는 것이 오류를 발생시킬 수도 있는 것이죠.
아래 코드와 같이 y = x; 라는 코드를 더해주면, y는 x가 가리키는 곳과 동일한 곳을 가리키게 됩니다.
따라서 *y = 13; 으로 저장하면 x가 가리키는 곳에도 동일하게 13으로 저장될 것입니다.
y = x;
*y = 13;
---
일정한 크기의 배열이 주어졌을 때, 그 크기를 키우려면 어떻게 해야 할까요?
단순하게 현재 배열이 저장되어 있는 메모리 위치의 바로 옆에 일정 크기의 메모리를 더 덧붙이면 되겠지만, 실제로는 다른 데이터가 저장되어 있을 확률이 높습니다.
따라서 안전하게 새로운 공간에 큰 크기의 메모리를 다시 할당하고 기존 배열의 값들을 하나씩 옮겨줘야 합니다.
따라서 이런 작업은 O(n), 즉 배열의 크기 n만큼의 실행 시간이 소요될 것입니다.
이 과정을 아래 코드와 같이 나타낼 수 있습니다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
//int 자료형 3개로 이루어진 list 라는 포인터를 선언하고 메모리 할당
int *list = malloc(3 * sizeof(int));
// 포인터가 잘 선언되었는지 확인
if (list == NULL)
{
return 1;
}
// list 배열의 각 인덱스에 값 저장
list[0] = 1;
list[1] = 2;
list[2] = 3;
//int 자료형 4개 크기의 tmp 라는 포인터를 선언하고 메모리 할당
int *tmp = malloc(4 * sizeof(int));
if (tmp == NULL)
{
return 1;
}
// list의 값을 tmp로 복사
for (int i = 0; i < 3; i++)
{
tmp[i] = list[i];
}
// tmp배열의 네 번째 값도 저장
tmp[3] = 4;
// list의 메모리를 초기화
free(list);
// list가 tmp와 같은 곳을 가리키도록 지정
list = tmp;
// 새로운 배열 list의 값 확인
for (int i = 0; i < 4; i++)
{
printf("%i\n", list[i]);
}
// list의 메모리 초기화
free(list);
}
위와 동일한 작업을 realloc 이라는 함수를 이용해서 수행할 수도 있습니다.
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int *list = malloc(3 * sizeof(int));
if (list == NULL)
{
return 1;
}
list[0] = 1;
list[1] = 2;
list[2] = 3;
// tmp 포인터에 메모리를 할당하고 list의 값 복사
int *tmp = realloc(list, 4 * sizeof(int));
if (tmp == NULL)
{
return 1;
}
// list가 tmp와 같은 곳을 가리키도록 지정
list = tmp;
// 새로운 list의 네 번째 값 저장
list[3] = 4;
// list의 값 확인
for (int i = 0; i < 4; i++)
{
printf("%i\n", list[i]);
}
//list 의 메모리 초기화
free(list);
}
---
데이터 구조는 우리가 컴퓨터 메모리를 더 효율적으로 관리하기 위해 새로 정의하는 구조체입니다.
일종의 메모리 레이아웃, 또는 지도라고 생각할 수 있습니다.
이번 강의에서는 데이터 구조중 하나인 연결 리스트에 대해 알아보겠습니다.
배열에서는 각 인덱스의 값이 메모리상에서 연이어 저장되어 있습니다.
하지만 꼭 그럴 필요가 있을까요? 각 값이 메모리상의 여러 군데 나뉘어져 있다고 하더라도 바로 다음 값의 메모리 주소만 기억하고 있다면 여전히 값을 연이어서 읽어들일 수 있습니다.
이를 ‘연결 리스트’라고 합니다. 아래 그림과 같이 크기가 3인 연결 리스트는 각 인덱스의 메모리 주소에서 자신의 값과 함께 바로 다음 값의 주소(포인터)를 저장합니다.
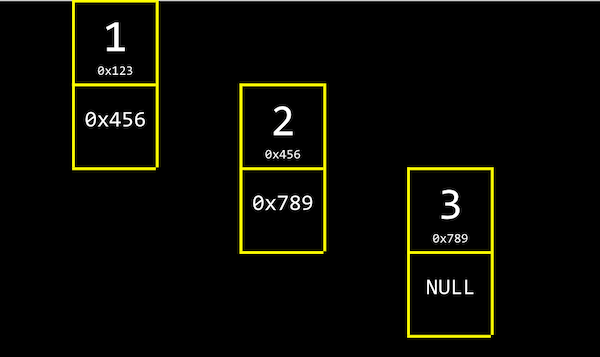
연결 리스트의 가장 첫 번째 값인 1은 2의 메모리 주소를, 2는 3의 메모리 주소를 함께 저장하고 있습니다.
3은 다음 값이 없기 때문에 NULL (\0, 즉 0으로 채워진 값을 의미합니다)을 다음 값의 주소로 저장합니다.
연결 리스트는 아래 코드와 같이 간단한 구조체로 정의할 수 있습니다.
typedef struct node
{
int number;
struct node *next;
}
node;node 라는 이름의 구조체는 number 와 *next 두 개의 필드가 함께 정의되어 있습니다.
number는 각 node가 가지는 값, *next 는 다음 node를 가리키는 포인터가 됩니다.
여기서 typedef struct 대신에 typedef struct node 라고 ‘node’를 함께 명시해 주는 것은, 구조체 안에서 node를 사용하기 위함입니다.
--
큐
큐는 메모리 구조에서 살펴봤듯이 값이 아래로 쌓이는 구조입니다.
값을 넣고 뺄 때 ‘선입 선출’ 또는 ‘FIFO’라는 방식을 따르게 됩니다. 가장 먼저 들어온 값이 가장 먼저 나가는 것이죠.
은행에서 줄을 설 때 가장 먼저 줄을 선 사람이 가장 먼저 업무를 처리하게 되는 것과 동일합니다.
배열이나 연결 리스트를 통해 구현 가능합니다.
스택
반면 스택은 역시 메모리 구조에서 살펴봤듯이 값이 위로 쌓이는 구조입니다.
따라서 값을 넣고 뺄 때 ‘후입 선출’ 또는 ‘LIFO’라는 방식을 따르게 됩니다. 가장 나중에 들어온 값이 가장 먼저 나가는 것이죠.
뷔페에서 접시를 쌓아 뒀을 때 사람들이 가장 위에 있는(즉, 가장 나중에 쌓인) 접시를 가장 먼저 들고 가는 것과 동일합니다.
역시 배열이나 연결 리스트를 통해 구현 가능합니다.
딕셔너리
딕셔너리는 ‘키’와 ‘값’이라는 요소로 이루어져 있습니다.
‘키’에 해당하는 ‘값’을 저장하고 읽어오는 것이죠. 마치 대학교에서 ‘학번’에 따라서 ‘학생’이 결정되는 것과 동일합니다.
일반적인 의미에서 ‘해시 테이블’과 동일한 개념이라고도 볼 수 있습니다.
역시 ‘키’를 어떻게 정의할 것인지가 중요합니다.
'BackEnd > CS' 카테고리의 다른 글
| 하드웨어 추상화 계층 HAL 이란? (0) | 2023.07.25 |
|---|

댓글