✅ 출력형식
%(a, b, c) 와 같이 표현하는 것 기억!
a, b = map(int, input().strip().split(' '))
print("%d + %d = %d" %(a, b, a+b))
✅ '구분자'.join(리스트)
리스트의 구성 원소들을 구분자를 이용하여 열거해서 하나의 문자열로 합쳐준다.
✅ divmod() 내장 함수
결과로 (몫, 나머지) 값을 갖는 튜플을 반환한다.
divmod(x, y) = (x // y, x % y)
✅ 리스트 안의 모든 값에 특정 함수를 적용시키려고 할 때 = map !
* 내 코드
def solution(strlist):
answer = []
for x in strlist:
answer.append(len(x))
return answer* 깔끔한 참고 코드
def solution(strlist):
answer = list(map(len, strlist))
return answer
✅ 배열 거꾸로 뒤집기
def solution(num_list):
return num_list[::-1]
✅ 리스트안에 특정 값이 몇 개 들어있는지 세는 함수 .count()
def solution(array, n):
return array.count(n)
✅ 7개 이하면 0이고 7개를 살짝 넘으면 1이다 ==> n-1으로 표현
def solution(n):
return (n - 1) // 7 + 1
✅ 딕셔너리 이용해서 특정 조건 매칭 해서 가독성 좋게 표현하기
def solution(price):
discount_rates = {500000: 0.8, 300000: 0.9, 100000: 0.95, 0: 1}
for discount_price, discount_rate in discount_rates.items():
if price >= discount_price:
return int(price * discount_rate)
✅문자열 이어붙일 때 : join을 적극활용하자, 반대는 .split()
def solution(my_string, n):
answer = ''
for x in my_string:
answer += x*n
return answer
보다는
def solution(my_string, n):
return ''.join(x*n for x in my_string)
✅ 서로 같은 원소 파악하기 : 집합을 이용해서 교집합 ... 중복은 교집합 ... !
def solution(s1, s2):
return len(set(s1)&set(s2));
✅ 숫자인지 알파벳인지 : isdigit(), isalpha()
✅ 문자열 안에 문자열 : 의외로 이렇게 된다
def solution(str1, str2):
return 1 if str2 in str1 else 2
✅ 제곱수 판별하기 문제에서 :
n**1/2.is_integer()
✅ 암호 해독 문제에서 :
리스트의 값 특정 배수 대로 값 뽑아올 수 있다... 문자열 슬라이싱 스텝도 가능하다.
def solution(cipher, code):
answer = cipher[code-1::code]
return answer
✅ 대소문자 바꾸기
.swapcase()
✅ 변수 명 붙이기
def solution(box, n):
return (box[0]//n) * (box[1]//n) * (box[2]//n)보다는
def solution(box, n):
x, y, z = box
return (x // n) * (y // n) * (z // n )
✅ 정렬하면 .sort() 는 결과 값 반환하는 함수가 아니다
주의. sorted(리스트) 를 사용해야 결과 값 반환하게 된다
✅ 람다함수 사용하기 / 출처 코딩도장 https://dojang.io/mod/page/view.php?id=2360
def solution(n, numlist):
return list(filter(lambda v: v%n==0, numlist))lambda 매개변수들: 식1 if 조건식 else 식2람다 표현식 안에서 조건부 표현식 if, else를 사용할 때는 :(콜론)을 붙이지 않습니다. 일반적인 if, else와 문법이 다르므로 주의해야 합니다. 조건부 표현식은 식1 if 조건식 else 식2 형식으로 사용하며 식1은 조건식이 참일 때, 식2는 조건식이 거짓일 때 사용할 식입니다.
특히 람다 표현식에서 if를 사용했다면 반드시 else를 사용해야 합니다. 다음과 같이 if만 사용하면 문법 에러가 발생하므로 주의해야 합니다.
list(map(lambda x: str(x) if x % 3 == 0, a))
SyntaxError: invalid syntax그리고 람다 표현식 안에서는 elif를 사용할 수 없습니다. 따라서 조건부 표현식은 식1 if 조건식1 else 식2 if 조건식2 else 식3 형식처럼 if를 연속으로 사용해야 합니다. 예를 들어 리스트에서 1은 문자열로 변환하고, 2는 실수로 변환, 3 이상은 10을 더하는 식은 다음과 같이 만듭니다.
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
list(map(lambda x: str(x) if x == 1 else float(x) if x == 2 else x + 10, a))
['1', 2.0, 13, 14, 15, 16, 17, 18, 19, 20]32.2.2 map에 객체를 여러 개 넣기
map은 리스트 등의 반복 가능한 객체를 여러 개 넣을 수도 있습니다. 다음은 두 리스트의 요소를 곱해서 새 리스트를 만듭니다.
>>> a = [1, 2, 3, 4, 5]
>>> b = [2, 4, 6, 8, 10]
>>> list(map(lambda x, y: x * y, a, b))
[2, 8, 18, 32, 50]
이렇게 리스트 두 개를 처리할 때는 람다 표현식에서 lambda x, y: x * y처럼 매개변수를 두 개로 지정하면 됩니다. 그리고 map에 람다 표현식을 넣고 그다음에 리스트 두 개를 콤마로 구분해서 넣어줍니다. 즉, 람다 표현식의 매개변수 개수에 맞게 반복 가능한 객체도 콤마로 구분해서 넣어주면 됩니다.
32.2.3 filter 사용하기
이번에는 filter를 사용해보겠습니다. filter는 반복 가능한 객체에서 특정 조건에 맞는 요소만 가져오는데, filter에 지정한 함수의 반환값이 True일 때만 해당 요소를 가져옵니다.
- filter(함수, 반복가능한객체)
먼저 def로 함수를 만들어서 filter를 사용해보겠습니다. 다음은 리스트에서 5보다 크면서 10보다 작은 숫자를 가져옵니다.
>>> def f(x):
... return x > 5 and x < 10
...
>>> a = [8, 3, 2, 10, 15, 7, 1, 9, 0, 11]
>>> list(filter(f, a))
[8, 7, 9]
✅ 리스트 회전
deque를 활용하면 rotate 함수를 이용해서 손쉽게 구현가능
from collections import deque
def solution(numbers, direction):
numbers = deque(numbers)
if direction == 'right':
numbers.rotate(1)
else:
numbers.rotate(-1)
return list(numbers)
✅ 리스트의 특정 값의 인덱스
def solution(array):
return [max(array), array.index(max(array))]
✅ 정수 확인
.is_integer()
✅ 람다와 map 적절히 활용한 예 (369게임)
def solution(order):
return sum(map(lambda x: str(order).count(str(x)), [3, 6, 9]))
✅ [인프런] 코딩테스트 강의 들으며 정리한 노트
## 0-4 반복문
a=range(1,11) : 순차적으로 리스트를 만드는 함수
for - else 구문 : for 가 break 없이 정상 종료되어야 else구문이 실행됨
## 0-7 문자열과 내장함수
msg.upper() : 대문자
msg.lower() : 소문자
msg.find('A') : 처음으로 발견된 인덱스 반환
msg.count('T') : 문자 개수 반환
msg.isupper() : 대문자이면 True
msg.islower() : 소문자이면 True
msg.isalpha() : 알파벳이면 True
msg.isdigit() : 숫자이면 True
msg.isdecimal() : int 형으로 변환 가능하면 True
isnumeric( ): 숫자값 표현에 해당하는 문자열이면 True
ord('A') : 아스키 넘버 출력
chr(65) : 아스키 넘버에 대응되는 문자 출력
## 0-8 리스트와 내장함수(1)
#참고
import random as r : 함수이름을 간단히
a = list(range(1, 6)) : a = [1, 2, 3, 4, 5]
#삽입
a.append(object) : 마지막 위치에 삽입
a.insert(index, object) : 특정 인덱스에 삽입
#삭제
a.pop() : 가장 마지막의 값을 삭제
a.pop(index) : 특정 인덱스의 값을 삭제(주의: 리스트에서 pop을 할 경우 자리를 한 번씩 옮겨야 해서 오래 걸린다.)
a.remove(object) : 대상 값을 삭제
#검색
a.index(object) : 대상 값의 인덱스를 반환
#기타 함수
sum(a) : 합 반환
max(a) : 최댓값 반환
min(a) : 최솟값 반환
a.sort() : 오름차순 정렬
a.sort(reverse=True) : 내림차순 정렬
## 0-9 리스트와 내장함수(2)
for x in enumerate(a) : x = (인덱스, 값)
- for index, value in enumerate(a) 와 같이 사용
if all(조건 for x in a): 모두 참인 경우
if any(조건 for x in a): 하나라도 참인 경우
(ex)
if all(60>x for x in a):
print("YES")
else:
print("NO")
<br>
<br>
## 0-10 2차원 리스트 생성과 접근
#표처럼 표현하기
for x in a:
print(x)
#표처럼 표현하기(숫자만)
for x in a:
for y in x:
print(y, end=' ')
print()
<br>
<br>
## 0-11 함수 만들기
함수를 사용하는 이유: 재 사용성, 유지 보수
파이썬에서는 다수의 값을 리턴할 수 있다.
ex) return a, b 튜플 형태로 리턴됨
<br>
<br>
## 0-12 람다 함수
함수이름 = lambda 변수: 리턴값
ex) list(map(lambda x:x+1, a))
## 0챕터 완!
## 전역변수와 지역변수
우선 순위: 지역변수가 없을 경우 전역변수를 가져온다.
다음과 같은 케이스에서 언어 번역이 먼저 된 후, 실행 되기 때문에
```python
def DFS():
if cnt == 5:
cnt = cnt+1 #이 줄에서 cnt는 지역변수가 생긴다고 언어 번역이 된다.
print(cnt)
```
그래서 번역시 cnt가 지역변수로 정해져 있는 상황에서
if cnt == 5: 를 판별하려고 하니까 에러가 발생하는 것.
만약 이런 경우에서 cnt가 지역변수로 할당되지 않고, 전역변수로 취급되길 원한다면
맨 처음에 global cnt 라고 명시해주어 전역변수 cnt를 활용할 수 있다.
#해당 문자의 유니코드 값 반환
#ord('a') = 97
#해당 문자가 알파벳인지 확인
#.isalpha()
#리스트를 문자열로 변환
#print(''.join(리스트))
#리스트의 특정 값 개수 반환
count = stages.count(i)
#중간값
(n-1)//2
#리스트 표현
left_side = [x for x in tail if x <= pivot]
#리스트 안에서 특정 값 삭제, 삽입 가능
리스트.append([x, y, a])
리스트.remove([x, y, a])
#리스트(문자열) 안에서 특정 값 조회
리스트.count()
#이진변환
bin()
#문자열 뒤집기
word = word[::-1]
#특정 값 변환: replace(old, new, [count])
num_dic = {"zero":"0", "one":"1", "two":"2", "three":"3", "four":"4", "five":"5", "six":"6", "seven":"7", "eight":"8", "nine":"9"}
#count_by_range(a, left, right)
정렬된 리스트에서 값이 left<=x<=right 에 속하는 원소 개수 반환
직접 bisect_right 과 bisect_left 를 이용해 정의하여 사용
return right - left 로
#시계 방향
dx = [-1, 0, 1, 0]
dy = [0, 1, 0, -1]
#n*m의 tmep 그래프 안에서 바이러스
def virus(x, y):
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
if 0<= nx <n and 0<= ny < m:
if temp[nx][ny] == 0:
temp[nx][ny] = 2
virus(nx, ny)
def solution(s):
answer = s
for key, value in num_dic.items():
answer = answer.replace(key, value)
return int(answer)
#람다식
# 2차원 리스트 90도 회전
def rotate_a_matrix_by_90_degree(a):
n = len(a)
m = len(a[0])
result = [[0]*n for _ in range(m)]
for i in range(n):
for j in range(m):
result[j][n-i-1] = a[i][j]
return result
#힙 자료구조
출발 노드로부터 가장 거리가 짧은 노드를 빠르게 찾을 수 있음
우선순위 큐: 우선순위 높은 데이터를 가장 먼저 삭제
import heapq
heap = []
heapq.heappush(heap, input)
heapq.heappop(heap)
재귀한도 풀기
import sys
sys.setrecursionlimit(10**7)
내장 :
1) eval()
2) sorted(대상, reverse, key)
itertools : 순열과 조합
data = ['a', 'b', 'c']
1) result = list(permutations(data, 3)) => [(a,b,c),(a,c,b),(b,a,c),(b,c,a),(c,a,b),(c,b,a) .... 총 3!=6개]
2) result = list(combinations(data, 2)) => [(a, b), (a, c), (b, c)] 총 3!/2! = 3개
3) product = list(product(data,2)) => [(a,a) (a,b )(a,c).... 총 3*3=9개]
4) combinations_with_replacement = list(combinations_with_replacement(data, 2)) => [(a,a), (a,b), (a,c), (b,b), (b,c), (c,c)] => 중복조합
heapq : 우선순위 큐
bisect : 이진탐색
1) bisect_left(a,x) : 리스트 a에 데이터 x를 삽입할 가장 왼쪽 인덱스
2) bisect_right(a,x) : 리스트 a에 데이터 x를 삽입할 가장 오른쪽 인덱스
정렬된 리스트에서 특정 범위에 속하는 원소의 개수를 빠르게 구할 수 있음
collections : deque, Counter
1) deque: append, appendleft, pop, popleft
2) counter = Counter(['a', 'b', 'c', 'b'])
print(counter['b']) => b가 등장한 횟수 출력
math : 팩토리얼, 제곱근, 최대공약수(GCD), 삼각함수, pi 등
1) factorial(x)
2) sqrt(x)
3) gcd(a, b)
4) math.pi 또는 math.e
#해시
import collections
def solution(participant, completion):
# 1. participant의 Counter를 구한다
# 2. completion의 Counter를 구한다
# 3. 둘의 차를 구하면 정답만 남아있는 counter를 반환한다
answer = collections.Counter(participant) - collections.Counter(completion)
# 4. counter의 key값을 반환한다
return list(answer.keys())[0]
print(solution(["marina", "josipa", "nikola", "vinko", "filipa"]
, ["josipa", "filipa", "marina", "nikola"]))
출처: https: // coding - grandpa.tistory.com / 85[개발자로
취직하기: 티스토리]
collections.Counter(리스트)
뺄셈 연산 가능
문자열.startswith(문자열)
zip()
동일 개수로 이루어진 자료형을 튜플로 묶어주는 함수
인덱스 짝이 없다면 없는 부분은 버려짐
✅ 임포트 할 때 :
import math 보다 from math import factorial 을 해야 함수 호출 시 편리하다.
1) factorial( )와 같이 함수 호출 가능
from math import factorial
def solution(n):
k = 10
while n < factorial(k):
k -= 1
return k2) math.factorial( )와 같이 함수 호출해야 함
그냥 factorial로 호출할 경우 다음과 같은 경고 문구가 나온다.
NameError: name 'factorial' is not definedimport math
def solution(n):
answer = 0
lt = 1
rt = 10
res = 1
while lt<=rt:
mid = (lt+rt)//2
if math.factorial(mid) > n:
rt = mid - 1
print("rt = %d" %rt)
else:
lt = mid + 1
res = mid
print("lt = %d" %lt)
return res
✅ 문자열 A로 '순서만 바꾸어' 문자열 B를 만들 수 있는가 ? : 정렬 이용
문자열 before와 after가 매개변수로 주어질 때, before의 순서를 바꾸어 after를 만들 수 있으면 1을, 만들 수 없으면 0을 return 하도록 solution 함수를 완성해보세요.
def solution(before, after):
return 1 if sorted(list(before)) == sorted(list(after)) else 0
---
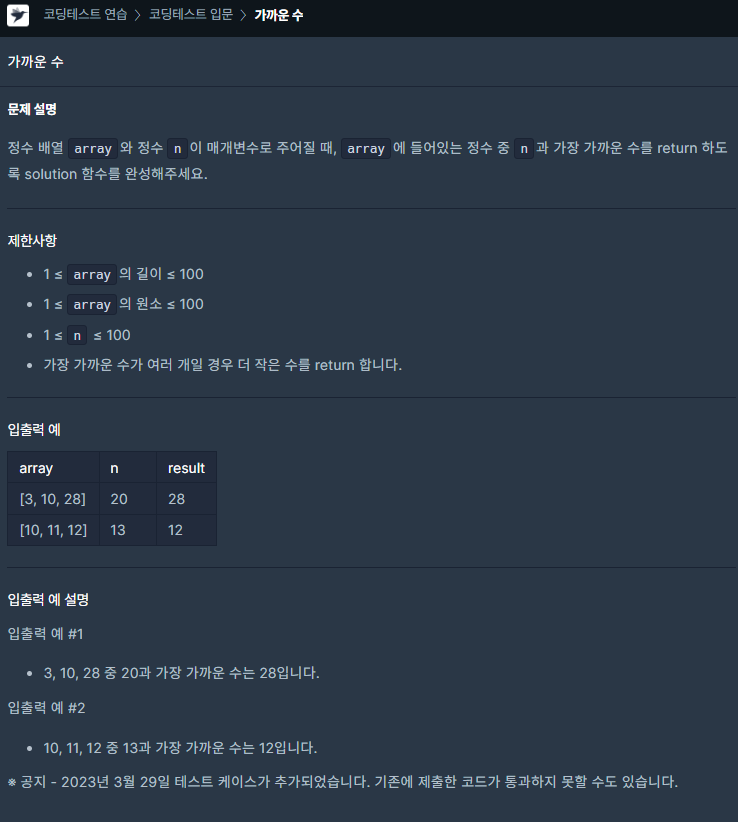
✅ 여러 개의 정렬 조건이 있을 때 : sorted(key =(기준1, 기준2) 이용할 생각 떠올리기
solution=lambda a,n:sorted(a,key=lambda x:(abs(x-n),x))[0]
✅ 리스트 뒤집는 연산 [::-1] O(N)
'알고리즘 문제풀이 > 요약 정리' 카테고리의 다른 글
| 문법 정리 (0) | 2023.11.01 |
|---|---|
| 딕셔너리, 힙 (0) | 2023.09.29 |
| 코테준비 (0) | 2023.05.09 |
| [1분 요약] 백트래킹(Backtracking)이란? (0) | 2022.07.27 |
| [1분 요약] 브루트 포스 알고리즘이란? (0) | 2022.07.20 |




댓글